

Demystifying Neural Networks: A Beginner’s Guide (2026)
Neural networks are everywhere in February 2026. Your phone cleans up blurry photos. A chatbot drafts an email. Spotify seems to guess your mood a little too well. It can start to feel like neural networks are some secret brain in a box.
They’re not. A neural network is mostly a pattern-finder that learns from lots of examples. It doesn’t “understand” in a human way, and it doesn’t wake up with ideas. It takes numbers in, pushes them through simple rules, and produces numbers out. The surprise is how good those simple rules can get when you stack many of them together.
This guide keeps things plain-English and light on math. You’ll learn what a neuron is, what training actually means (forward pass, loss, backpropagation), and what the main network types do (feedforward nets, CNNs, RNNs and LSTMs, transformers, GANs and VAEs). You’ll also get a practical “what should I try first?” path, without pretending it will be easy overnight.
What a neural network really is, explained like a team of tiny decision-makers
 Neural networks act like many small decision-makers passing signals forward (created with AI).
Neural networks act like many small decision-makers passing signals forward (created with AI).
A helpful way to picture a neural network is a team of tiny decision-makers. Each one is simple. Each one gets a few numbers, does a quick calculation, then passes a result to the next group.
Those tiny decision-makers are usually called neurons (or nodes). A neuron has a few basic parts:
- Inputs: the numbers it receives (pixels, words turned into IDs, sensor values, etc.).
- Weights: how much each input should matter. Think of weights as little importance knobs.
- Bias: a small nudge that shifts the neuron’s tendency up or down.
- Activation: a rule that decides what signal to send forward.
Put neurons into layers, and you get the classic structure:
- Input layer: receives raw numbers.
- Hidden layers: do most of the work, step by step.
- Output layer: produces the final prediction (a label, a number, a probability list, or something else).
When people say “deep learning,” they usually mean a neural network with many hidden layers. More layers can learn more complex patterns. That said, deeper isn’t always better. Sometimes it’s just harder to train, slower, and easier to mess up.
One more idea that clears up a lot of confusion: deep learning often learns features for you. In older machine learning, you’d hand-pick features, like “average brightness” or “number of edges.” With neural nets, the hidden layers can discover useful features from raw inputs, as long as you have enough data and the setup makes sense.
A neural network isn’t magic. It’s a lot of tiny, boring math choices stacked into something useful.
A quick picture-in-your-head example: how an image turns into numbers
![]() An image becomes a grid of values, and deeper layers can learn edges and shapes (created with AI).
An image becomes a grid of values, and deeper layers can learn edges and shapes (created with AI).
When a neural network looks at a photo, it doesn’t see a cat, a face, or a sunset. It sees numbers.
A grayscale image can be a grid where each pixel has a value from dark to light. Even a tiny 28×28 image becomes 784 numbers. A color image is often three channels (red, green, blue), so the count jumps fast.
The early hidden layers might learn simple patterns, like edges or corners. Later layers can combine those into shapes, like circles or textures. Deeper layers can combine shapes into higher-level patterns, like “eye-like region” or “wheel-like curve.” Nothing in the network is labeled “eye.” It just learns that certain number patterns often show up together.
This is why neural nets can feel spooky. They don’t store a list of rules. They store lots of learned weights that turn raw numbers into useful signals.
Why activation functions matter (and why you can ignore the math for now)
If a neuron only did “weighted sum + bias,” the whole network would act like a fancy straight-line rule. That works for some problems, but it hits a wall fast.
An activation function adds a simple twist that lets the network model curved, messy real-world patterns.
The most common one you’ll hear about is ReLU. In plain words, ReLU means: keep positive values, drop negative ones to zero. It’s popular because it’s simple and usually trains well.
In output layers, you might see different activations depending on the task:
- Sigmoid often turns a score into a 0-to-1 value for yes/no decisions.
- Softmax turns a set of scores into probabilities that add up to 1, which helps when picking one class among many (spam vs not spam, or cat vs dog vs rabbit).
You don’t need to memorize the math today. Just remember what activations do: they give the network room to learn patterns that aren’t straight lines.
How neural networks learn: guess, measure the mistake, then adjust
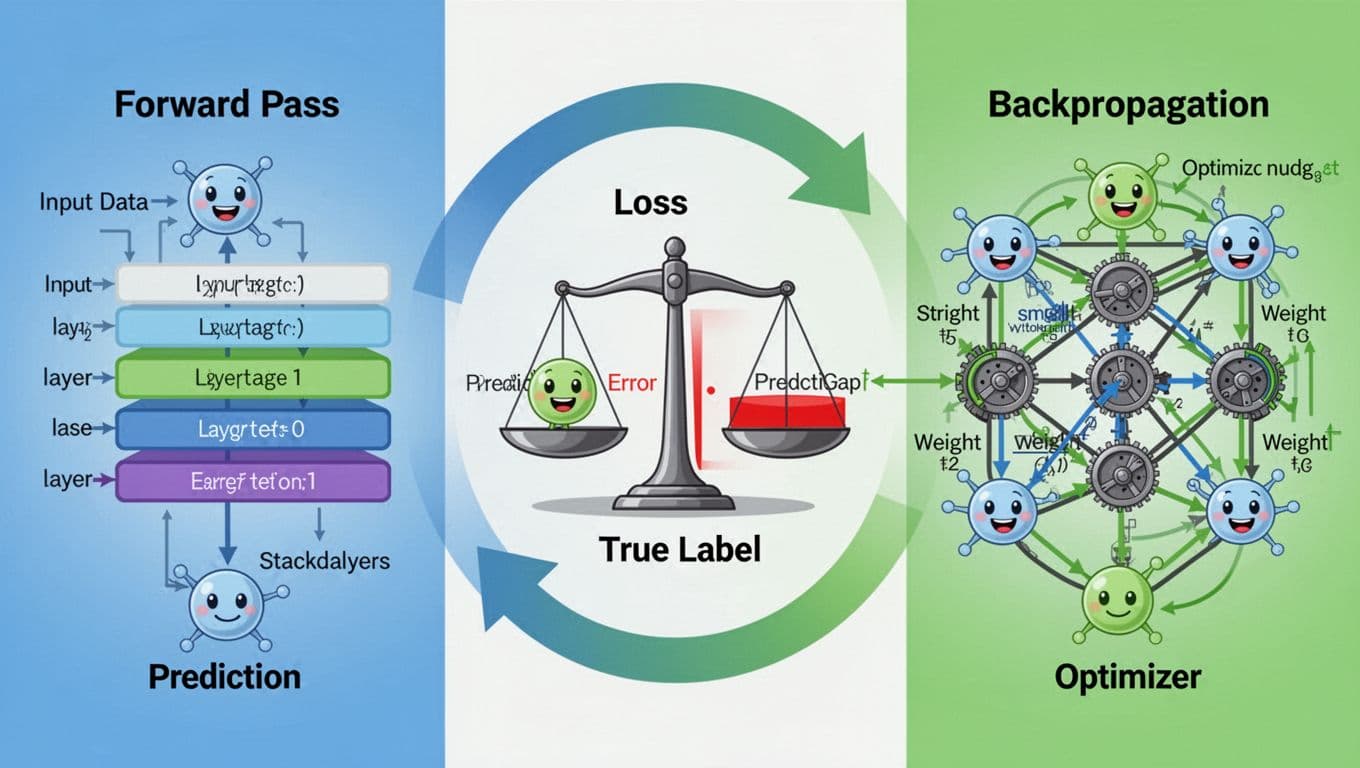 Training repeats a loop: predict, measure error, then adjust weights (created with AI).
Training repeats a loop: predict, measure error, then adjust weights (created with AI).
Training a neural network is less like “teaching” and more like coaching with endless feedback. It makes a guess, checks how wrong it was, then tweaks itself. Repeat that thousands or millions of times.
The training loop usually looks like this:
- Forward pass: send the input through the network to get a prediction.
- Loss computation: measure how far the prediction is from the correct answer.
- Backpropagation: figure out which weights deserve the blame for the error.
- Optimization step: update weights to reduce future loss.
That “blame assignment” step is backpropagation. Under the hood, it uses calculus (the chain rule). As a beginner, you can treat it like a system that tells each weight, “you pushed the answer the wrong way, fix it a bit.”
The optimizer is the part that applies the fix. You might hear names like gradient descent, SGD (stochastic gradient descent), or Adam. Different optimizers adjust weights in slightly different ways, but the goal stays the same: reduce loss.
A tiny example helps, even if it’s a bit toy-ish. Suppose a neuron takes two inputs:
- inputs: x1 = 2, x2 = 1
- weights: w1 = 0.3, w2 = -0.1
- bias: b = 0.2
It computes a score: (2 * 0.3) + (1 * -0.1) + 0.2 = 0.7.
If you apply ReLU, the output is still 0.7 (because it’s positive). If the score were -0.7, ReLU would output 0.
Training is basically adjusting those weights and bias so the final output matches the labels more often.
One practical note: neural nets often need lots of data and a lot of compute. That’s why people train on GPUs and use mini-batches (small chunks of data) to keep things moving.
Loss vs accuracy: why the model trains on one thing but you track another
Loss is the training signal. Metrics are the report card.
During training, the network needs a number that changes smoothly when weights change. Loss functions usually work well for that. Cross-entropy loss is a common choice for classification, even if it feels abstract at first.
Meanwhile, humans like simple metrics. Accuracy makes sense quickly. For imbalanced problems, accuracy can lie, so people also track precision and recall (especially in fraud detection, medical screening, or spam filtering).
So you might see a run where loss keeps dropping, but accuracy barely moves. That can be normal for a while. The model might be getting more confident about the right answers, even before it flips more answers from wrong to right.
If you only remember one thing, remember this: the model learns by lowering loss, but you judge it with metrics.
Overfitting and underfitting, the two beginner traps that waste the most time
Overfitting happens when a model memorizes the training data. It looks great in practice runs, then falls apart on new data. It’s like studying the exact answers to last year’s exam, then getting a different exam.
Underfitting is the opposite. The model is too simple (or trained too little), so it never learns the real pattern. It performs poorly on both training and test data, which is frustrating in a different way.
A few fixes show up again and again:
- For overfitting: add more data, simplify the model, use regularization, add dropout, and stop early (early stopping). Also, check your validation split, because a bad split can trick you.
- For underfitting: train longer, increase model capacity, improve input features, or use a better architecture for the job.
In real life, overfitting is more common when the dataset is small or repetitive. A network trained to recognize product photos might “learn” the studio background instead of the product. Then it fails on a customer photo in messy lighting. It didn’t learn “product,” it learned “photo booth.”
Common neural network types and when you would use each one
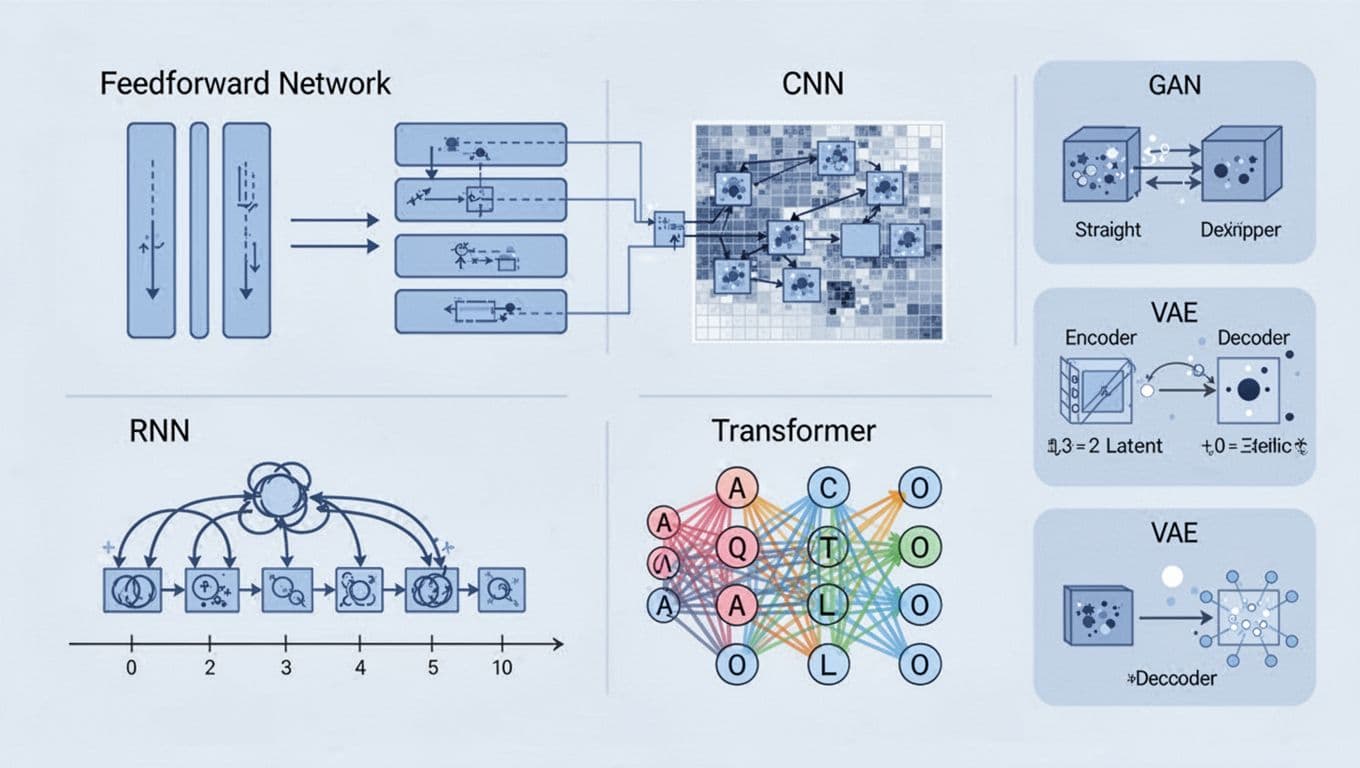 A quick visual of the major neural network families people use today (created with AI).
A quick visual of the major neural network families people use today (created with AI).
Not all neural networks are built the same. Different designs fit different data shapes.
Feedforward neural networks (FNNs) move information one way, from input to output. They’re a solid first step for beginners, and they still work well on tabular data, like “predict churn from customer stats” or “classify spam using message features.”
Convolutional neural networks (CNNs) specialize in grids, like images and video frames. They use small filters to pick up local patterns, then build them into bigger ones. CNNs show up in face unlock, medical imaging, quality checks in factories, and photo apps that sharpen or remove noise.
Recurrent neural networks (RNNs) and their better-behaved cousin LSTM handle sequences. They can model “what happened before,” which helps with speech, time-series, and text. That said, many language tasks have shifted away from RNNs toward transformers, because transformers handle long-range context better.
Transformers dominate modern language models and many multi-modal tools. They often power chatbots, translation, summarization, and code assistants.
On the generative side, you have networks that create new stuff:
- GANs (generator vs discriminator) can produce realistic images, but they can be tricky to train.
- VAEs (variational autoencoders) learn a compressed representation and reconstruct from it, which can help with generation and anomaly detection.
These models show up in everyday products, including recommendation systems (Netflix and Spotify style personalization), speech-to-text, search ranking, and content creation tools. At the same time, they can inherit bias from training data, and generative models can be misused for deepfakes. It’s not a side issue anymore, it’s part of using the tech responsibly.
Transformers in plain English: attention means “focus on the important parts”
When you read a sentence, you don’t give every word equal attention. Your brain naturally focuses on the words that change the meaning.
Transformers copy that idea with a mechanism called attention. Attention lets the model decide which parts of the input matter most for the current step. If the sentence is long, the model can still connect ideas that are far apart, like a name at the start and a pronoun later.
This is a big reason transformers replaced older sequence models in many tasks. They handle long context better, and they train efficiently in parallel.
In practice, transformers power most chatbots people use now, plus translation systems, summarizers, and tools that classify or extract info from documents. They still make mistakes, though. Sometimes they sound confident while being wrong, which means you have to verify outputs in serious settings.
GANs and VAEs, two ways to generate new stuff (and why they are not the same)
A GAN has two networks that compete. The generator tries to create fake samples (like images). The discriminator tries to spot what’s real and what’s fake. As they compete, the generator usually improves, because it learns how to fool a stronger critic.
A VAE feels calmer. It learns to compress data into a smaller hidden code (often called a latent space), then reconstructs the original. Generation happens by sampling from that latent space and decoding back into an image or signal. VAEs often produce more varied outputs, but they can look softer or less sharp than GAN outputs.
Both approaches can help with useful things, like data augmentation or synthetic training examples. Still, the misuse risk is real. If a model can generate convincing faces or voices, someone will try to abuse it. So it matters where the data came from, what consent exists, and what guardrails you put in place.
A simple path to start learning without getting overwhelmed
Neural networks are easier to grasp once you drop the mystique. They’re built from neurons that pass numbers through layers. During training, they repeat a loop: forward pass, compute loss, backpropagate the error, then update weights with an optimizer. From there, different architectures handle different data, like CNNs for images, transformers for language, and GANs or VAEs for generation.
If you’re new, keep your next steps small and concrete:
First, learn the basics of data splits, loss, and simple metrics. Next, build a tiny feedforward network on an easy dataset (MNIST digit recognition is the classic for a reason). After that, try a CNN on images. Then, if language work interests you, experiment with transformer tooling.
Free environments like Google Colab help a lot, because you can use a GPU without setting up a full machine. For frameworks, PyTorch and Keras are both beginner-friendly, so pick one and stick with it for a while.
Progress comes from repeating the loop: build something small, measure it, break it, fix it, and run it again. That sounds basic because it is, and that’s the point.






